

目录:
1. 概述编辑
本文将介绍如何在 Linux 系统中手动配置高可用抽取集群。
如您计划部署FineBI6.0抽取集群,请先联系帆软技术支持或帆软销售代表,进行初步评估、以及环境信息等的确认。
技术支持联系方式:「服务平台>在线支持」、电话「400-811-8890」
如您未联系过帆软,自行进行抽取集群的部署,无法保证遇到未知风险后能够及时处理。
2. 准备步骤编辑
手动配置高可用集群之前,请先提前准备好以下内容。
| 操作步骤 | 说明 | |
|---|---|---|
| 1 | 准备服务器环境 | 准备工程节点+负载均衡+状态服务器+文件服务器+配置库部署环境 请确保各工程节点和组件所在服务器间内网互通 请确保各工程节点和组件所在服务器系统时间一致 推荐环境:工程部署推荐环境 支持环境:集群工程部署支持环境 |
| 2 | 部署数据库 | 部署数据库,作为工程的外接数据库备用,优先推荐高可用主备模式数据库 用户只需要部署并启动该数据库。 支持的数据库类型请参考:配置外接数据库 |
| 3 | 部署负载均衡 | 部署负载均衡,推荐Keepalived+Nginx部署方案 只需要安装配置Keepalived,安装Nginx 无需启动,无需修改nginx.conf配置文件 参考文档:Keepalived+Nginx部署方案 |
| 4 | 部署状态服务器 | 部署状态服务器,推荐部署Redis集群 请确保Redis集群启动,推荐部署6节点,部署在6个服务器上 参考文档:Linux系统安装配置Redis集群 |
| 5 | 部署文件服务器 | 部署文件服务器,推荐部署NAS |
| 6 | 部署工程节点 | 先只部署一个工程节点,请勿启动该工程 部署方法请参考单机部署的「部署包部署」或「独立部署」 |
3. 配置并启动工程编辑
3.1 配置Linux系统参数
需要为Linux修改三个系统参数,以确保后续抽取集群正常运行。
3.2 配置Redis日志
对于FineBI6.0抽取集群,状态服务器Redis是比较关键的组件,需要配置下日志,便于日后排查问题。
在redis.conf文件中,日志默认配置为:logfile ""
新增/修改为:logfile "redis.log"
配置后日志会自动生成在src目录下。
3.3 新建spider.cluster.properties(可选)
如需调整端口等配置,可执行本节操作。如无需调整,可跳过。
在%BI_HOME%\webapps\webroot\WEB-INF\config目录下,新建spider.cluster.properties文件。
文件中包含三行内容:
| 设置内容 | 说明 |
|---|---|
| spider_grpc_port=xxx | 设置spider引擎rpc端口,如不配置,默认端口为50051 确保配置一个空闲可用的端口即可 |
| bi_conf_rpc_port=xxx | 设置新配置框架的rmi,如不配置,默认端口为50200 确保配置一个空闲可用的端口即可 |
| is_sync_node=true | 设置工程节点属性,如不配置,默认为同步节点 false:非同步节点 true:同步节点 |

3.4 启动并登录平台
启动该FineBI工程节点。
1)确保配置外接数据库
管理员登录FineBI系统,点击「管理系统>系统管理>常规>外接数据库」,确保系统已配置外接数据库。
高可用集群推荐选择高可用主备模式数据库作为外接finedb数据库。

2)安装插件
高可用集群的文件一致性设置建议为NAS,该功能依赖「共享外部目录」插件。
该插件一般默认已安装,请检查「管理系统>插件管理」中是否存在该插件,如不存在请提前安装。

3)进入集群配置界面
管理员登录数据决策系统,点击「管理系统>智能运维>集群配置」。
下文所有配置操作均在本页面完成。

4. 配置状态服务器编辑
准备内容:
高可用集群的状态服务器建议使用Redis集群作为状态服务器。
请先确保Redis集群已启动,否则工程无法成功连接它。
请准备好Redis集群的密码(如果没有密码可不准备,如果配置了 Redis 密码,则Redis 各个节点需要使用统一的密码)
请准备好Redis集群各节点的主机IP和端口号(不建议使用域名,请准备内网IP)
配置步骤:
1)开启「状态服务器」按钮。
2)选择缓存系统为「Redis集群」。
3)如有密码,输入密码;如无密码,忽略该步骤。
4)根据Redis集群节点数量,添加节点。输入每个节点的主机IP和端口。
5)配置完毕后,点击「测试连接并保存」,若无异常则可保存成功。

效果预览:
成功开启的状态服务器如下图所示:

5. 配置MQ内置编辑
MQ内置功能专为「容器化部署」的集群准备,非容器化手动部署集群无需关注该步骤,直接跳过。
容器化部署 安装的工程,一般默认配置了 rocketmq 组件,rocketmq可替换 Redis 消息队列一部分功能。
若未配置rocketmq,默认使用redis。
若配置了rocketmq,rocketmq和redis同时生效,负责不同功能。
6. 配置文件服务器编辑
准备内容:
高可用集群的文件一致性设置建议选择「文件服务器共享>共享外部目录」。
请先确保第四章状态服务器配置成功,否则无法配置文件服务器。
请先确保第三章的「共享外部目录」插件安装成功,否则无法选择。
请先确保NAS文件服务器已启动,否则工程无法成功连接它。
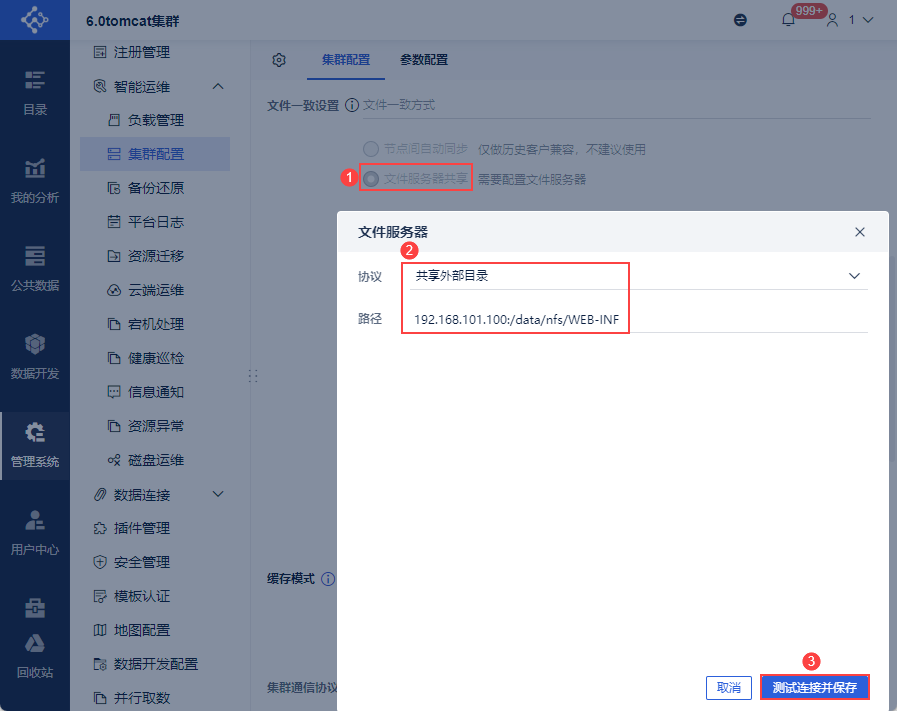
配置步骤:
1)将该工程节点的%FR_HOME%\webapps\webroot\WEB-INF文件夹拷贝到文件服务器中。
2)为文件服务器中的 WEB-INF 文件夹赋予权限,Linux 系统中为 777 权限。
3)完整复制文件服务器中该WEB-INF文件夹的路径地址,形如192.168.101.100:/data/nfs/WEB-INF
4)文件一致性设置选择「文件服务器共享」
5)在弹出框中协议选择「共享外部目录」
6)路径设置为第三步复制的文件服务器中WEB-INF文件夹的路径地址
7)配置完毕后,点击「测试连接并保存」,若无异常则可保存成功。
7. 配置缓存模式编辑
高可用集群的缓存模式建议选择「关闭缓存」。

8. 配置集群通信协议编辑
高可用集群的集群通信协议建议选择「TCP」。

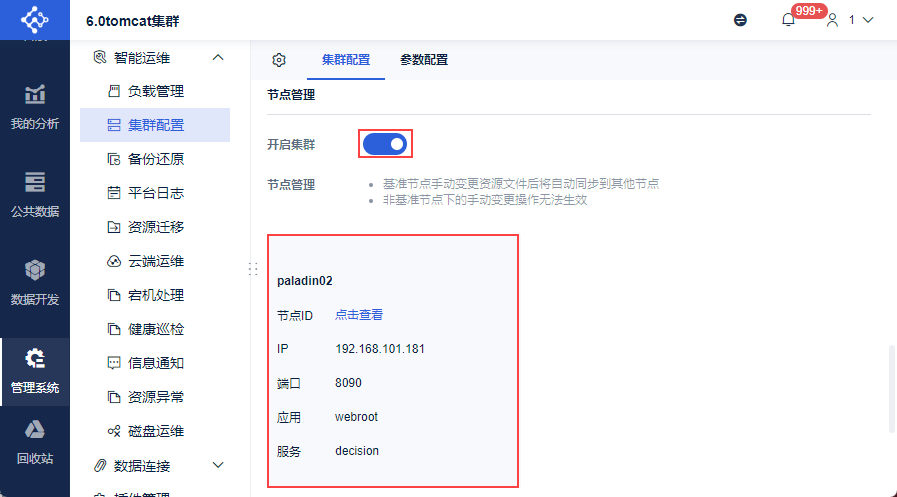
9. 确认单节点集群配置成功编辑
1)开启「开启集群」按钮。
2)重启该节点工程。
3)再次查看「管理系统>智能运维>集群配置」,在节点管理处出现本工程节点。
至此,该工程节点与外接数据库、状态服务器、文件服务器的对接完全成功,单节点集群部署成功。
10. 配置多节点工程编辑
1)部署集群的其他工程节点
部署方法请参考单机部署的「部署包部署」或「独立部署」。
2)拷贝工程文件
将上文的单机集群节点的%BI_HOME%\webapps\webroot文件夹,分别拷贝覆盖新部署的其他工程节点的%BI_HOME%\webapps\webroot文件夹。
3)修改spider.cluster.properties(可选)
如需调整端口等配置,可执行本节操作。如无需调整,可跳过。
在每个新工程节点的%BI_HOME%\webapps\webroot\WEB-INF\config目录下,找到spider.cluster.properties文件,修改相关配置。
| 设置内容 | 说明 |
|---|---|
| spider_grpc_port=xxx | 设置spider引擎rpc端口,如不配置,默认端口为50051 确保配置一个空闲可用的端口即可 |
| bi_conf_rpc_port=xxx | 设置新配置框架的rmi,如不配置,默认端口为50200 确保配置一个空闲可用的端口即可 |
| is_sync_node=true | 设置工程节点属性,如不配置,默认为同步节点
四节点以下集群,建议所有集群节点都配置为true 五节点以上集群,建议其中四个节点为true,其他为false |
4)删除cluster.properties
找到新工程节点的%BI_HOME%\webapps\webroot\WEB-INF\config目录,如果存在cluster.properties文件,删除该文件。
5)重启这些新工程节点
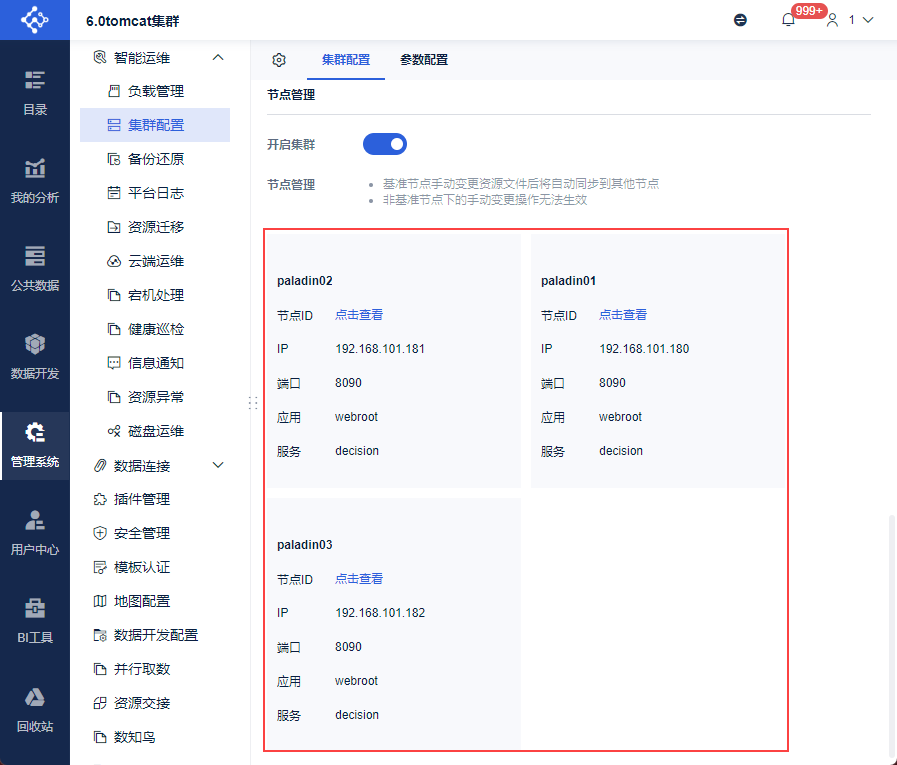
11. 确认多节点集群配置成功编辑
管理员依次登录每一个工程节点,查看「管理系统>智能运维>集群配置」,在节点管理处出现所有工程节点信息。
至此,所有工程节点与外接数据库、状态服务器、文件服务器的对接完全成功,多节点集群部署成功。
12. 配置负载均衡编辑
负载均衡可以通过各种算法来分配用户请求到不同的节点上,以获得更好的性能和负载均衡效果。
高可用集群的负载均衡建议选择「Keepalived+Nginx」。
请先确保已参考文档进行部署:Keepalived+Nginx部署方案
配置步骤:
1)修改nginx.conf
以该文件作为基础:抽取集群nginx.zip
参考文档修改nginx.conf文件:Linux系统安装配置Nginx


2)重启Nginx组件。
13. 确认高可用集群配置成功编辑
在浏览器输入ip:负载均衡端口号/status查看健康页面,可以看到工程各个节点的健康状态。
至此,一个高可用的多节点集群就部署成功了。

14. 确认抽取集群启用编辑
高可用集群生效后,抽取集群自动生效。
管理员登录FineBI,点击「管理系统>系统管理>抽取集群」,即可查看节点信息。
SYNC为同步节点,ASYNC为非同步节点,具体说明请参见:抽取集群管理界面。
用户可以尝试添加、更新、查询抽取的基础表和自助数据集,如果无异常说明已成功搭建抽取集群。

15. 下一步操作编辑
| 下一步操作 | 说明 |
|---|---|
| 集群注册 | 若单机工程原本注册了,升级为多节点集群后,需要重新注册 |
| 产品安全加固指导手册 | 参考文档提高产品安全性 |
| 运维监控指导手册 | 参考文档提高运维稳定性 |
| 运维平台 | 建议为集群配置运维平台工具 |