

1. 概述编辑
1.1 版本
| FineBI 版本 | 功能变动 |
|---|---|
| 6.0 | - |
| 6.0.2 | 数据类型识别逻辑优化,对数据位数进行更准确的判断 |
| 6.0.3 | 新增BI参数「智能数据解释」 新增BI参数「抽取查询超时时间」 |
1.2 功能简介
FineBI 在系统管理里提供了配置一些 BI 参数和调优参数的功能,方便系统管理和项目实施人员简单快捷的了解当前系统配置,并在界面上进行快速设置。
管理员登录FineBI系统,进入「管理系统>系统管理>常规」,可以看到 BI 和 Spider 参数配置的页面。如下图所示:
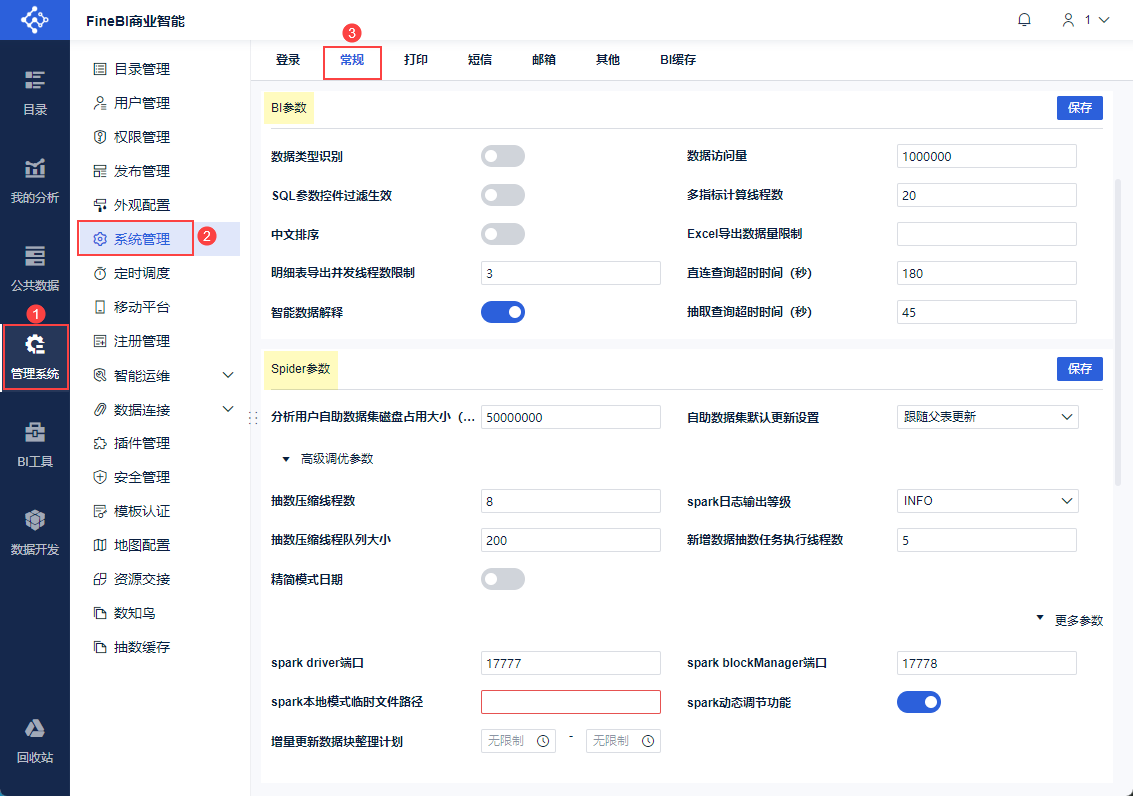
2. BI 参数编辑
| 参数 | 定义 | 默认值 | 修改后是否 需要重启工程 |
|---|---|---|---|
| 数据类型识别 | 1)无论是否开启,有小数位数时字段始终被识别为数值类型 2)不开启数据类型识别时,超过15位的识别为文本类型,小于等于15位的识别为数值类型 3)开启数据类型识别后始终识别为数值类型(double),double有效精度为15位(2^52),所以当数值长度超过15位时就可能发生精度丢失的情况 4)在未开启参数的情况下添加的表(直连和分布式):
| 关闭 | 是 |
| 数据访问量 | 数据访问量限制了可读入服务器内存的数据行数。并非所有大数据量计算场景都会将所有数据读入内存,FineBI Spider 引擎具有智能的内存使用策略 配置过低,将影响数据计算准确性。 配置过高,系统有宕机风险。 单位:行 可配置区间:[0,10000000] 建议设置区间:[10000,1000000],建议保持默认值 | 1000000 | 是 |
| SQL参数控件过滤生效 | 控件绑定SQL参数功能与过滤功能是否同时生效 默认关闭,表示不生效 | 关闭 | 否 |
| 多指标计算线程数 | 控制多指标计算时的线程数 配置过低,涉及多指标计算场景时计算速度将会降低 配置过高,涉及多指标计算场景时可能会影响其他任务的吞吐量 建议保持默认值 20 建议设置区间:[10, 20] | 20 | 是 |
| 中文排序 | 是否使用中文排序 默认关闭,表示不使用中文排序 开启后,抽取数据的表需要重新抽数 详情参见:排序 1.4 节 | 关闭 | 是 |
| Excel 导出数据量限制 | 用户导出 Excel 时可能会超出数据量限制,提供该参数便于用户设置,超过限制导出将直接报错 单位:单元格(行*列) 配置范围:0-2000000000 建议配置范围:0-1000000000 | 空 | 否 |
| 明细表导出并发线程数限制 | 当多个用户同时导出数据量很大的 Excel 时,可能会超过并发数,影响用户使用,因此提供该参数,可设置同时进行明细表导出的用户数。超过限制导出,业务员需等待。 配置范围:1-10 建议配置范围:1-5,建议保持默认值 | 3 | 是 |
直连查询超时时间(秒) | 当仪表板中组件过多,组件查询时间会过长,或者仪表板中某个组件查询时间过长,导致后续 BI 请求被阻塞,容易误认为产品宕机。 此时可设置直连查询超时时间,所有实时数据查询超时之后将会中止查询,防止异常慢查询阻塞其他正常查询。 组件返回如下报错: 组件查询时间超过Xmin,查询中断 单位:秒 建议配置范围:10-300 生效范围:BI直连除获取表结构之外的所有查询请求 | 180 | 否 |
| 智能数据解释 | 安装数据解释插件后此配置才生效 关闭后,手动配置过的数据解释才能触发,以避免数据解释的滥用 | 开启 | 否 |
| 抽取查询超时时间(秒) | 所有抽取数据查询超时之后将会中止查询,防止异常慢查询阻塞其他正常查询 | 45 | 否 |
3. Spider 参数编辑
Spider 参数包含基础参数和高级调优参数,如下图所示:
注:其中「Spider 参数」适用于抽取数据,实时数据不适用。

3.1 基础参数
分析用户自助数据集磁盘占用大小(单元格)参数只影响 数据存放路径 (默认%FineBI%/bin/ROOT 文件夹)下数据文件夹的磁盘占用空间大小,服务器磁盘空间 1T 以上可考虑修改,1T 以下保持默认配置即可。
| 参数 | 定义 | 默认值 | 修改后是否需要重启工程 |
|---|---|---|---|
分析用户自助数据集磁盘占用大小 注:若修改过大会导致磁盘占满,引起宕机。 | 限制用户制作的自助数据集(分析性质)可更新的最大数据量。可有效保护系统磁盘的健康使用。 配置过低,会导致大量自助数据集更新失败。配置过高,会引发磁盘占满。重启后生效。 单位:单元格(行*列) 建议设置区间:[10,000,000, 100,000,000] 详情请参见:数据量说明 | 50,000,000 | 是 |
| 自助数据集默认更新设置 | 自助数据集单表更新是否跟随父表更新 详情请参见:自助数据集单表更新 | 跟随父表更新 | 是 |
3.2 高级调优参数(常用)
| 参数 | 定义 | 默认值 | 修改后是否 需要重启工程 |
|---|---|---|---|
| 抽数压缩线程数 | 抽取数据时,分片(压缩&写入)线程的数量 在内存很小(不超过4G)并且无法扩大内存的情况下,可以调小该线程,减轻内存压力 配置过低,数据更新速度将会减缓。 配置过高,数据更新时可能会影响其他任务的吞吐量 建议保持默认值 8。 建议设置区间:[4, 16] | 8 | 是 |
| 抽数压缩线程队列大小 | 抽取数据时,未处理的分片等待队列长度 在内存很小(不超过4G)并且无法扩大内存的情况下,可以调小队列长度,减轻内存压力 配置过低,数据更新速度将会减缓 配置过高,数据更新时可能会影响其他任务的吞吐量 建议保持默认值 200 建议设置区间:[100, 200] | 200 | 是 |
| Spark日志输出等级 | spark日志输出等级,标准输出流,输出在 Tomcat 的 catalina.out 文件内或者 BI 的 nohup 文件内 可选项为:INFO、WARN、ERROR、DEBUG。
| INFO | 是 |
| 新增数据抽数任务执行线程数 | 新增数据的抽数任务同时执行的线程数 在内存很小(不超过4G)并且无法扩大内存的情况下,可以调小该线程数,减轻内存压力 配置过高,数据更新时可能会影响其他任务的吞吐量 建议保持默认值 5 建议设置区间:[1, 5] | 5 | 是 |
| 精简模式日期 | 精简模式开启时,日期字段在进行数据抽取时,只提前生成少量分组类型,加快生成速度,减少占用空间 未生成的分组在进行计算时可能会有性能损失 | 关闭 | 是(且需重新更新数据) |
3.3 更多参数
| 参数 | 定义 | 默认值 | 修改后是否 需要重启工程 |
|---|---|---|---|
| Spark Driver端口 | 建议设置区间:[1001, 65535] | 17777 | 是 |
| Spark blockManager端口 | 建议设置区间:[1001, 65535] | 17778 | 是 |
| Spark本地模式临时文件路径 | Spark写临时文件的目录,需给足一定的空间,修改至SSD挂载路径可提升Spark处理关联、SparkSql查询的性能 注:集群版该参数无效,需要在服务器端配置。 | null (Linux下实际为/tmp) | 是 |
| Spark动态调节功能 | Spark动态 根据计算数据量调节task的数目 开启后对于小数据量的计算性能提升明显 | 开启 | 是 |
| 增量更新数据块整理计划 | 在这个时间段内,增量更新任务不会执行合并操作,提升增量更新的速度 设置格式 hh:mm:ss-hh:mm:ss 示例 10:10:10-12:12:12 | 关闭 | 是 |